VidGuard-R1:

Detecting AI-Generated Videos via Multimodal LLMs Fine-Tuned with RL

Abstract
The rapid rise of AI-generated videos creates urgent risks, from misinformation to reputational harm, making reliable detection tools essential. Beyond accuracy, detectors must also explain their decisions to ensure transparency. We present VidGuard-R1, the first video authenticity detector that fine-tunes a multimodal large language model (MLLM) with group relative policy optimization (GRPO). VidGuard-R1 combines strong accuracy with clear reasoning. We build a challenging dataset of 140k real and generated videos designed to test detection difficulty. Using Qwen-VL with GRPO and two reward models focused on temporal artifacts and generation complexity, VidGuard-R1 achieves state-of-the-art zero-shot results and surpasses 95% accuracy after further training. Case studies show it also provides precise, interpretable explanations for its predictions.
Highlights
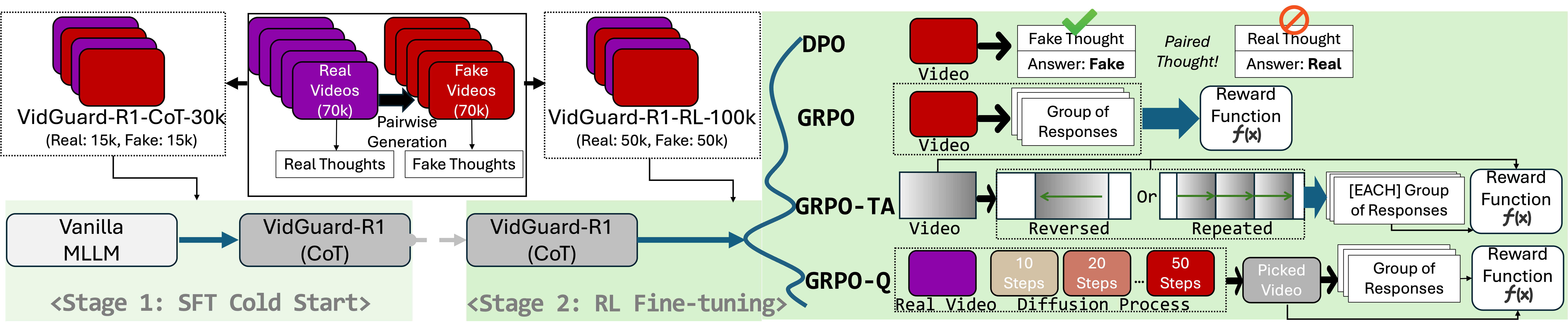
- VidGuard-R1 is the first video authenticity detector that fine-tunes a multimodal LLM with GRPO. It combines the pretrained knowledge of MLLMs for accurate classification with reinforcement learning for effective exploration. To further boost performance, we introduce two reward models that capture temporal artifacts and generation complexity across diffusion steps.
- We build a dataset of 140k real/fake video pairs for AI-generated video detection. Using state-of-the-art generators and controlled synthesis, we ensure that distinguishing real from fake remains highly challenging.
- VidGuard-R1 achieves state-of-the-art zero-shot accuracy above 95% on existing benchmarks, and case studies demonstrate its ability to deliver accurate, interpretable explanations.
Example Videos
AI Video (Dreamvideo)
1. Motion Consistency: The astronaut riding the horse appears to be in motion, but the movement looks somewhat unnatural. The horse's legs and the astronaut's body seem to move in a way that doesn't quite align with real-life physics. The motion looks slightly jerky and inconsistent, which is a common sign of AI-generated content.
2. Lighting Consistency: The lighting in the video seems to be consistent with what one might expect in a real outdoor setting. However, the lighting on the astronaut and the horse is somewhat flat and lacks the depth and variation that would be present in a real scene.
3. Texture Artifacts: The textures of the astronaut's suit and the horse's coat appear somewhat artificial. There are no visible details that would suggest a real-life material.
4. Physics Violations: The most striking aspect is the physics violation. An astronaut in a spacesuit would not be able to ride a horse in a real-world scenario.
AI Video (LaVie)
The texture of the camera and the person's skin appears quite smooth and lacks the fine details that you'd typically expect to see in a real photograph. The lighting seems consistent, but the lack of depth and detail in the texture suggests this might not be a real image.
If this were a real photograph, we would expect to see more subtle variations in the skin tone and the camera's surface, which are often lost in AI-generated images. The edges of the camera and the person's hair also seem a bit too sharp and clean, which is not typical of real-world photography.
The overall lack of fine detail and the slightly artificial appearance of the textures strongly suggest that this image has been generated by an AI model.
Real Video
1. Motion Consistency: The hands in the video appear to be moving in a way that is consistent with human motion. The way the fingers are positioned and the way the materials are being handled suggest natural human movement. There are no sudden or unnatural movements that would typically be indicative of AI-generated footage.
2. Lighting Consistency: The lighting in the video seems to be consistent across the frames. There are no harsh shadows or overly bright highlights that would suggest a digital manipulation. The lighting appears to be natural, possibly from an overhead source.
3. Texture Artifacts: The textures of the materials being handled, such as the wire wreath and the fabric, look realistic. There are no overly smooth or pixelated textures that are often seen in AI-generated images. The details in the fabric and the wire are clear and consistent.
4. Physics Violations: The actions being performed, such as wrapping the fabric around the wire wreath, are physically plausible. There are no obvious physics violations, and the way the fabric is being manipulated is consistent with real-world behavior.
Real Video
1. Motion Consistency: The hand movements in the video appear smooth and natural. There are no sudden jerks or unnatural movements that one might expect from an AI-generated image. The hand seems to be manipulating the fan in a way that is consistent with human interaction.
2. Lighting Consistency: The lighting in the video is consistent across the frames. There are no noticeable changes in brightness or shadows that would indicate a shift in lighting conditions. This suggests that the video was likely taken in a controlled environment.
3. Texture Artifacts: The textures of the fan, the hand, and the wooden surface appear realistic. There are no overly smooth or pixelated areas that are typical of AI-generated images. The details in the fan's wires and the hand's skin texture are well-rendered.
4. Physics Violations: The hand is interacting with the fan in a way that follows the laws of physics. The hand is holding the fan and appears to be turning it, which is a realistic action. There are no physics violations.
AI Video (Show-1)
1. Motion Consistency: This image is a still frame, so there's no motion to assess here. This is a neutral point for evaluation.
2. Lighting Consistency: The lighting in the image is consistent with what one would expect from a sunset. The light source (the sun) is positioned low on the horizon, casting long shadows and creating a warm, diffused light across the sky and water. This is a realistic depiction.
3. Texture Artifacts: In a real photograph, the texture of the sky, clouds, and water would be more varied and detailed. The image appears smooth and lacks the fine details that would be present in a real photograph. This could be a sign that the image is AI-generated.
4. Physics Violations: There are no obvious physics violations in this image, as the sun is positioned correctly and the colors are natural. However, the combination of smooth texture and absence of fine detail points towards the image being AI-generated.
AI Video (Sora)
1. Motion Consistency: The motion of the woman and the people around her seems smooth and realistic, which is a good sign. However, upon closer inspection, there are some subtle inconsistencies that might indicate AI generation.
2. Lighting Consistency: The lighting appears natural and consistent, suggesting it might be filmed indoors with ambient light. However, the shadows and highlights on the cake and the woman's face seem a bit too perfect, lacking the slight imperfections that are usually present in real-world footage.
3. Texture Artifacts: The texture of the woman's clothing and the cake appears slightly unnatural, with some areas looking a bit too smooth or too sharp, which is often a sign of AI generation.
4. Physics Violations: The physics of the scene seem to hold up well. The woman is blowing out the candles, and the smoke is rising naturally. However, the slight inconsistencies in texture and lighting suggest that it might be an AI-generated video.
AI Video (SVD)
1. Motion Consistency: In the video, the two individuals appear to be engaged in a conversation. Their movements seem natural and consistent with human behavior. There are no sudden jerks or unnatural movements that would suggest AI generation.
2. Lighting Consistency: The lighting in the video appears to be natural, likely from the stadium lights. There are no harsh shadows or overly bright highlights that would be inconsistent with real-world lighting conditions.
3. Texture Artifacts: Upon close inspection, the textures of the clothing, the background, and the environment appear natural. There are no obvious digital artifacts or distortions that are typically seen in AI-generated images. The details in the uniforms, the grass, and the stadium elements all look realistic.
4. Physics Violations: The individuals in the video are standing upright and interacting in a way that is physically plausible. However, despite these realistic elements, advanced AI techniques might be able to mimic real-world conditions very closely, suggesting this could still be AI-generated.
@inproceedings{park2026vidguardr,
title={VidGuard-R1: {AI}-Generated Video Detection and Explanation via Reasoning {MLLM}s and {RL}},
author={Kyoungjun Park and Yifan Yang and Juheon Yi and Shicheng Zheng and Muhammad Muaz and Yifei Shen and Dongqi Han and Caihua Shan and Lili Qiu},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=gXjOsBcXIR}
}